正则表达式(regular expression)
根据其英文翻译,re模块
作用:用来匹配字符串。 在Python中,正则表达式是特殊的字符序列,检查一个字符串是否与某种模式匹配。
设计思想:用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,就认为它“匹配”了,否则,该字符串就是不合法的。
格式:正则表达式也是用字符串表示的,注意:带引号
| 格式 | 作用 | 备注 |
| \d | 匹配一个数字 | |
| \w | 匹配一个字母或数字或下划线 | |
| \s | 匹配一个空格 | |
| . | 匹配任意字符,但不包含换行符'\n' | 'py.'可以匹配'pyc', 'pyo', 'py!' |
| * | 匹配前一个字符0个到任意个 | |
| + | 匹配前一个字符1个到任意个 | |
| ? | 匹配前一个字符0个到1个 | |
| {n} | 匹配前一个字符n次 | |
| {n,m} | 匹配前一个字符n到m次,n个,n+1个……m个 | 不是n减m个字符,或m减n个字符 |
| [0-9a-zA-Z\_] | 匹配一个字符,限定范围中的任意类型都可以 | 字符个数=1,并不是匹配每种类型一个;不能为0个,空字符串会报错 |
| [0-9a-zA-Z\_]+ | 至少有一个字符,限定范围中的任意类型都可以 | 字符个数>=1 |
| [0-9a-zA-Z\_]* | 任意个字符(包含0个),限定范围中的任意类型都可以 | 字符个数>=0,只是比+表示的字符多了一个0 |
| [0-9a-zA-Z\_]? | 0个或1个字符,限定范围中的任意类型都可以 | 字符个数=0个,1个 |
| [a-zA-Z\_][0-9a-zA-Z\_]* | 匹配由字母或下划线开头,后接任意个字符,限定范围中的任意类型都可以 | |
| [a-zA-Z\_][0-9a-zA-Z\_]{0,19} | 更精确地限制了变量的长度,前半部分只匹配一个字符,{0,19}是限定后半部分字符的长度 | 所以总的字符长度是1+{0,19}={1,20} |
| ^ | 表示行的开头 | ^\d,表示必须以数字开头 |
| $ | 表示行的结束 | \d$,表示必须以数字结尾 |
| A|B | 可以匹配A或B | (P|p)ython可以匹配'Python' 或'python' |
| re模块的match方法 | 匹配字符串 | |
| re模块的split方法 | 切分字符串 | |
| re模块的group方法,groups方法 | 分组 |
re模块
使用Python的r前缀,就不用考虑转义的问题
r'^(\d{3})-(\d{3,8})$'
匹配
match( )方法判断是否匹配,如果匹配成功,返回一个match对象;否则,返回None
match(pattern, string) :pattern:正则表达式的字符串, string:要判断、匹配的字符串
re.match(r'\d\d\d','223')
切分字符串
split( )方法
# p的这三个例子,带不带r都没影响,而且, ;都没有使用转义符\,但是都运行成功;不明白原因p=re.split(r"[\s;,]+","a b, g ;hd;s231")print("p:",p)p1=re.split("[\s;,]+","a b, g ;hd;s231")print("p1:",p1)p2=re.split("[\s\;,]+","a b, g ;hd;s231")print("p2:",p2)p3=re.split("[\s\;\,]+","a b, g ;hd;s231")print("p3:",p3) 
分组
正则表达式还能提取子串,格式:用()表示的就是要提取的分组 group
例1:
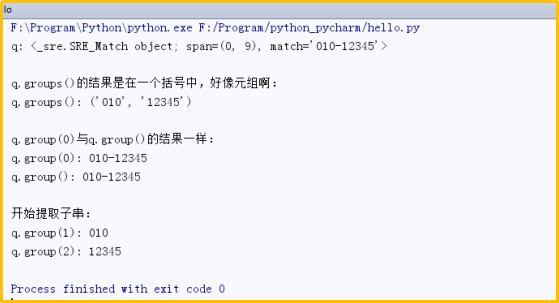
q=re.match('^(\d{3})-(\d{5}$)',"010-12345")print("q:",q)print("")print("q.groups()的结果是在一个括号中,好像元组啊:")print("q.groups():",q.groups()) #注意q.groups()和q.group(0)的显示结果是不一样的print("")print("q.group(0)与q.group()的结果一样:")print("q.group(0):",q.group(0))print("q.group():",q.group())print("")print("开始提取子串:")print("q.group(1):",q.group(1))print("q.group(2):",q.group(2)) 运行结果:
例2:这个例子中的正则表达式可以直接识别合法的时间。但是,识别日期时,正则表达式无法做到完全验证:
'^(0[1-9]|1[0-2]|[0-9])-(0[1-9]|1[0-9]|2[0-9]|3[0-1]|[0-9])$'
对于‘2-30’,‘4-31’这样的非法日期,用正则表达式还是识别不了,或者说写出来非常困难,这时就需要程序配合识别了。
t = '19:05:30'm = re.match(r'^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$', t)print("m.groups():",m.groups())print("m.group():",m.group())print("m.group(0):",m.group(0))print("m.group(1):",m.group(1))print("m.group(2):",m.group(2))print("m.group(3):",m.group(3))print("m.group(4):",m.group(4)) #一共只有3个子串,提取第4个时会报错 运行结果:

贪婪匹配
正则表达式默认是贪婪匹配,也就是匹配尽可能多的字符。
re.match(r'^(\d?)(0*)$', '102300').groups()里" \d? "这种格式会报错,而"\d+?"就运行正常了
结果分析: 由于\d+采用贪婪匹配,直接把后面的数字,包括0全部匹配了,结果0*只能匹配空字符串了。 这种情况下,必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个问号?就可以让\d+采用非贪婪匹配
r=re.match(r'^(\d+)(0*)$', '102300').groups()print("r:",r)r1=re.match(r'^(\d*)(0*)$', '102300').groups()print("r1:",r1)r2=re.match(r'^(\d{4})(0*)$', '102300').groups()print("r2:",r2)#这是非贪婪匹配r4=re.match(r'^(\d+?)(0*)$', '102300').groups() #这里不能使用\d?,而要使用\d+?,好像\d不能直接跟?相连print("r4:",r4)r3=re.match(r'^(\d{3})(0*)$', '102300').groups() #如果是\d{3},那么102300中间的3就会匹配不上,所以报错print("r3:",r3)r5=re.match(r'^(\d?)(0*)$', '102300').groups() #这里不能使用\d?,而要使用\d+?,好像\d不能直接跟?相连print("r5:",r5) 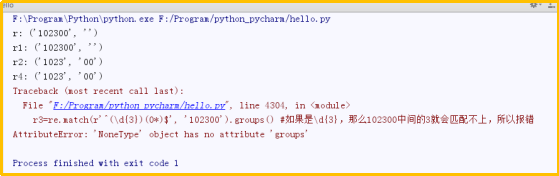

预编译
在Python中使用正则表达式时,re模块内部会干两件事情:
1、编译正则表达式,如果正则表达式的字符串不合法,就会报错;
2、用编译后的正则表达式去匹配字符串。
如果一个正则表达式要重复使用几千次,出于效率的考虑,可以预编译这个正则表达式,以后使用时就不需要编译这个步骤了,直接进行第二步匹配。
注意:编译后生成Regular Expression对象,由于该对象包含了正则表达式,所以调用对应的方法时不用给出正则表达式了。
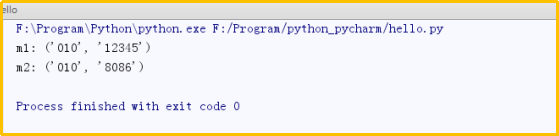
import rere_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')m1=re_telephone.match('010-12345').groups()m2=re_telephone.match('010-8086').groups()print("m1:",m1)print("m2:",m2) 运行结果:
h=re.match('[0-9a-zA-Z\_]*','B6585668944jyejye')print("h:",h) #给定的字符串中间是空格,空字符,不属于中括号中的任一类型,所以只匹配到空格前的字符串h1=re.match('[0-9a-zA-Z\_]*','_B658 5668944jyejye') print("h1:",h1) #第一个就是空格,所以直接匹配0个,然后返回结果h2=re.match('[0-9a-zA-Z\_]*',' _B6585668944jyejye')print("h2:",h2) 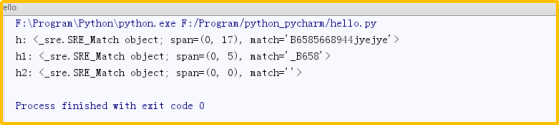
参考网址:
https://www.liaoxuefeng.com/wiki/1016959663602400/1017639890281664